

In our day to day life, we identify repetitive patterns almost inadvertently. Take gym workouts, for example, we can identify the patterns and count repetitions effortlessly. But, what if we want a machine to do the same task, by monitoring a live video input stream, that too in real time. Can it be done?
Convolutional Neural networks to the rescue
What is Convolutional Neural Network?
A convolutional neural network (CNN) is a specific type of artificial neural network that uses perceptrons, a machine learning unit algorithm, for supervised learning, to analyze data. CNN applies to image processing, natural language processing and other kinds of cognitive tasks.
Like other kinds of artificial neural networks, a convolutional neural network also has an input layer, an output layer, and various hidden layers. Some of these layers are convolutional, using a mathematical model to pass on results to successive layers. This simulates some of the actions in the human visual cortex.
CNN is a fundamental example of deep learning, where a more sophisticated model pushes the evolution of artificial intelligence by offering systems that simulate different types of biological human brain activity.
How CNN solves our problem?
With the advent of CNN, various tasks involving computations on visual imagery have been made possible. Let’s analyze how can CNN be used to solve our very specific classification problem – ‘Given an input video, count the number of repetitions of a cyclic activity.’
The designed classifier solution consists of two major components –
- A Monitoring system, which
- Detects a new exercise,
- Decides on when to count an exercise,
- Aggregates the output from the core system, and
- Choose between different time scales detectors
- Core image processing block (using CNN) which does the actual counting of repetitions
We’ve trained our core image processing block (CNN) to analyze a set of 20 well sampled non-consecutive frames at a time, which will output a cycle length for the repeating action. The training is done on synthesized data containing 20 frames of size 50×50 with cycle lengths in the between 3 to 10 (frames). This choice is made because a cycle length < 3 is too short, whereas, a cycle length > 10 will not repeat in 20 frames. For a wider coverage of repetition lengths, the CNN is applied to the video frames sampled at multiple time scales. The selection among the time scales is done by examining the entropy of the probabilities assigned by the CNN. Lower the entropy, higher is the confidence in the result of CNN classification. The monitoring system will start counting when the entropy remains low for a defined time. Whereas a significant shift in entropy indicates the end of the exercise. At the end of an exercise, the monitoring system resets itself to the initial state.
What’s happing behind the scenes?

Fig 1. The CNN architecture used for calculating the length of the cycle.
The input is given to a convolution layer C1 with 40 filters of size 5x5x20, which encodes temporal patterns across the entire 20 frames. This is followed by Max pooling and convolution/maximization layers(C3-M6), resulting in output with a spatial resolution of 4×4. A hidden layer of size 500 is taken and is followed by a fully connected layer of output size 8, which classifies the cycle length in 8 classes 3,4…9,10.
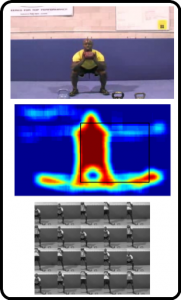
Fig 2: First row shows a frame of video, the second row depicts the heat map used in order to detect ROI and in the third row, the ROI is estimated. These 20 nonsequential frames form the input to the CNN classifier.
To achieve a highly robust system, a 20 frames block is pre-processed to find RoI (Region of Interest) and resulting frames are resized to 50×50 px. This results in an input vector of 50x50x20. RoI is assumed to be rectangular in shape as the relevant motion occurs only in a small part of the image.
We employ multiple detectors for different time scales, each having a fixed sub-sampling parameter N. Each detector collects uniformly sampled blocks of 20 frames from a video of total 20N frames. Between consecutive blocks, the second sampled frame in the first block becomes the first sampled frame in the next block. These blocks are sequentially analyzed by CNN and the cycle length is labeled for all N blocks. These labels are merged together to produce a real-time repetitions counter.
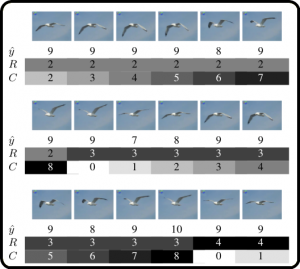
Fig 3. In the first video block, the ŷ is estimated to be 9. R is set to 2 (floor(20/9)) and C is set to 20-2*9 = 2. The blocks are processed sequentially and the value of R is increased when C==ŷ.
For every processed video block, we have a label ŷ and the associated probability p(ŷ) computed by softmax function. For each detector, we maintain 2 counters –
- R, which tells the current repetition count, and
- C, which tells the number of frames elapsed since the last cycle was detected.
Once the repetitive action is detected on the video block, the cycle length ŷ is predicted by CNN. Counter R is updated as R = floor(20/ŷ) and Counter C = 20- ŷ*R. After the next video block is analyzed, a new label ŷ is calculated and the frame counters are updated as C = C+1 and R is not incremented until C==ŷ. Once C == ŷ, C is set to 0, R is incremented and one repetition is detected. This process continues for all the blocks.
The sampling rate N corresponding to each detector is set in accordance with the expected frequency. The cycle length given by the CNN classifier varies from 3 to 10 frames. This, in turn, gives us a repeated action in duration ranging between 3N/30 to 10N/30 seconds, for a video with 30 fps. We categorized our detectors, to capture rapid, moderate and slow actions and assign respective N accordingly. For our case, we used detectors with N as 2, 5 and 8. For a wider coverage on the types of motions in the data, more detectors can be included.
Each detector provides a vector of probabilities derived from the softmax layer pi, i=3…10 for each video frame. The CNN model was trained to minimize cross entropy loss from these probabilities. We can choose entropy of predictions H(p) = -Σ pi * log(pi). When H(p) is low, the detector is more likely to output a valid length of the cycle. So, H(p) can be used to decide if a repeated action is taking place.
For real-time counting with the 3 detectors, a global counter is used. The 3 detectors calculate for cycle lengths every 2,5 or 8 frames. After 40 frames (LCM of 2,5,8), we synchronize among the cycle length predictions from the 3 detectors by comparing the average entropy of the detectors. The detector with the lowest entropy is selected and count difference of R counter from the previous reading (taken 40 frames ago) is added to the global count.
What’s so special about it?
The approach we discussed –
- Processes videos and counts repetitions in Real-time, which is very important for any practical application
- Completely autonomous,
- Robust enough to handle variable repetitions in length
- It also supports multiple time scales, making it more versatile.
We’d designed this solution to measure the repetitions of a single person. But the same approach can be modified to count the repetitions of multiple persons entering the frame, or even identify people performing particular tasks, making it even more human-like.
Applications of such a system are enormous, health clubs, gym competitions can use this as is to reduce overhead costs. Whereas the modified solution discussed above can identify people wandering in restricted zones and their activities, which can be very useful to monitor secured areas in factories, powerplants, banks or even public places like airports.
Feel free to reach out to us if you’ve any suggestions for improvements.