

With the rapid growth of Internet, there has been huge volume of information that is produced and shared by various administrations in nearly every business, industry and other fields. Research has shown that currently over 80% of all data is unstructured. It is being constantly generated in the form of call center logs, web page, e-mail message, documents, social media, survey records, blogs, satellite imagery, sensors data, health records, audio, images, video etc. Data with some form of structure may still be characterized as unstructured if its structure is not helpful for the processing task at hand.
The rise of Web 2.0 applications such as Facebook, Twitter, YouTube allows anyone to upload their own data – be it photos, video, chat to share with others, to comment and to organize. These opportunities come pair with their own set of challenges – how can we make the best use of this information?
Data Collection:
The first challenge is to gather the relevant data. Accurate data collection is essential to maintain the integrity of analysis. Collecting more or less data, both lead to future issues. Just because data can be collected from any device or third-party resource doesn’t mean we should. Collecting terabytes of sensor data from manufacturing floors or systems in the field is of little use if marketing team wants to track customer sentiment. In retail, suppose we want to give product recommendations to a customer. In this case user’s click and purchase history needs to be collected from mobile applications as well as website. Collecting additional information such as user’s gender, place, device information and age plays an important role in further improving the results. So it is very necessary to align business goals before embarking on an unstructured data initiative.
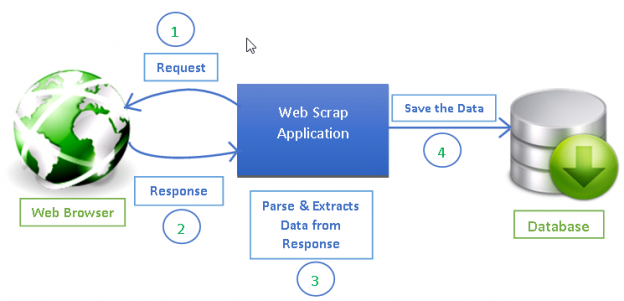
Web Scraping is one of the first steps to collect data from the web. It involves writing a bot which crawls different websites or pages and downloads content from them. There are various web scraping tools available to gather information from web. We use both BeautifulSoup and Scrapy for data collection.
Scrapy: It is an application framework for writing web spiders that crawls web sites and extract data from them. One of the main advantages of Scrapy is that requests are scheduled and processed asynchronously. It also separates out the logic to extract data so that a simple change in layout doesn’t result in us having to rewrite out spider from scratch.
BeautifulSoup: It is a very popular web scraping Python library which constructs a Python object based on the structure of the HTML code and also deals with bad markup reasonably well. It is a helpful utility to get specific elements out of a webpage
lxml: It is an XML parsing library (which also parses HTML) with a pythonic API based on Element tree. It is not part of the Python standard library.
The complexity of this process is highly dependent on the design of web page. For example to extract all headers alongwith their content in case 1 would be much simpler than case 2.
Case 1 : <div class=”content”><section id=”section1”><h>Header1</h><p>Content1</p> </section><section id=”section2”><h>Header2</h><p>Content2</p> </section></div>
Case 2: <div class=”content”><div><h>Header1/h><p> Content1</p ><h>Header2</h> <p>Content2</p></div></div>
Social Media APIs are very useful for collecting social data. These APIs allows to query social network platforms for posts, users, channels, demographic data etc. All major social networks such as Facebook, Twitter, Instargram etc provide these APIs. For example: Twitter Search API queries against the indices of recent or popular Tweets. It can be used to check what customers are saying in general about by searching hashtag of the brand (https://api.twitter.com/1.1/search/tweets.json?q=%23brandname). The result is a JSON array with the tweet’s text, favorites, retweets, urls, creation date, and other attributes.
Data Cleaning:
Data in the real world is dirty. It is incomplete(lacking attribute values, lacking certain attributes of interest), noisy(containing errors or outliers) and inconsistent(containing discrepancies in codes or names). So, after collecting data, next step is to clean it. It deals with detecting and removing errors, inconsistencies and unwanted noise. When data is collected from multiple sources, the need for data cleaning increases because of different representation of same data.
Data cleaning ranges from simple task such as escaping html characters, removal of stop words and punctuations to some complex tasks such as grammar checking, splitting attached words and spelling correction. To achieve better insights, it is necessary to play with clean data.
Some real-world examples where data cleaning is needed:
Data collected from web is a mess! It consists of extra line breaks, extra commas in random places, funky styling etc. It is necessary to clean this data. Scrapy, the tool used for data collection can be helpful is some basic cleaning as well.
In retail, catalog cleaning is one of the necessary steps. Suppose the seller is tagging the product with some attributes. Common observed scenarios include using different words to mean same thing such as “averagerating”, ”rating”, ”avgrating”; using inconsistent case such as “color”, “COLOR”; stopwords etc. It won’t be possible to do proper analysis until all attributes are mapped to same.
Social media data is highly unstructured as well. Misspellings during data entry, missing information, bad grammar, use of slang, presence of unwanted content like URLs, stopwords, expressions etc are the common causes.
Data Interpretation:
After data has been cleaned, next step is to gather some useful insights from it. Techniques such as text mining and natural language processing(NLP) provide different methods to find patterns or interpret the unstructured data. To analyse a preprocessed data, it needs to be converted into features. Depending upon the usage, text features can be constructed using techniques such as Syntactical Parsing, Entities / N-grams / word-based features, Statistical features, and word embeddings
Text mining, often referred to as text analytics, is defined as the process or practice of examining large collections of written resources in order to generate new information. The purpose of text analytics is to discover relevant information in text by transforming text into data that can be used for further analysis. It accomplishes this through the use of a variety of analysis methodologies; natural language processing (NLP) is one of them. NLP is a way for computers to analyze, understand, and derive meaning from human language in a smart and useful way. It deals with different aspects of language: phonology, morphology, syntax, semantics and pragmatics.
By utilizing NLP and its components, one can organize the massive chunks of text data, perform numerous automated tasks and solve a wide range of problems such as –
Text Classification: It is defined as a technique to systematically classify a text object (document or sentence) in one of the fixed category. It is really helpful when the amount of data is too large, especially for organizing, information filtering, and storage purposes.
Text Matching/Similarity: Important applications of text matching includes automatic spelling correction, data de-duplication etc.There are various techniques to do this like Levenshtein Distance,Phonetic Matching,Flexible String Matching,Cosine Similarity etc.
Document to Information: This involves parsing of textual data present in documents to analyzable and clean format.
Text Summarization: Given a text article or paragraph, summarize it automatically to produce most important and relevant sentences in order.
Sentiment analysis: It is the process of determining whether a piece of writing is positive, negative or neutral. A common use case of this is to discover how people feel about a particular topic.
2 Comments. Leave new
This is truly useful, thanks.
I spent a lot of time to find something like this